

【Linux存储系列教程】ceph的架构和原理
一、ceph的介绍
- Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
- 目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
二、ceph的特性
- 高性能
- 采用
CRUSH算法实现数据均衡分布 - 支持上千存储节点,支持TB到PB级的数据
- 采用
- 高可用性
- 高可扩展性
- 特性丰富
- 支持三种存储接口:块存储、文件系统存储、对象存储
- 支持多种语言驱动
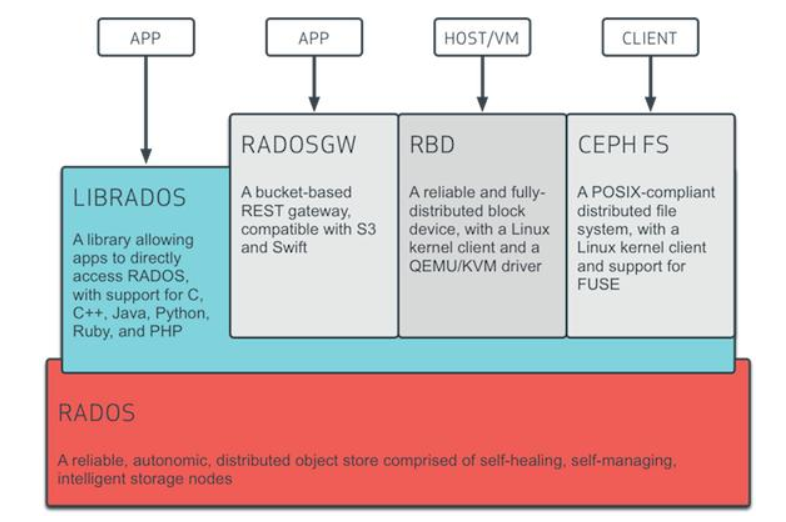
三、ceph的核心概念

1. Monitor
一个
ceph集群需要多个monitor集群,它们通过paxos同步数据
用于保存OSD元数据
2. OSD
Object Storage Device对象存储设备
**负责响应客户端请求、返回具体数据的进程 **
一个ceph集群一般都存在多个OSD
3. MDS
Ceph Metadata Server是cephFS依赖的元数据服务
4. Object
ceph最底层的存储单元
每个object包含元数据和原始数据
5. PG
Placement Groups一个PG包含多个OSD
为了更好地分配、定位数据
6. RADOS
Reliable Automatic Distributed Object Store实现数据分配、Failover等集群操作
7. Libradio
访问
RADIO的库
提供PHP、Ruby、Java、Python、C和C++支持
8. CRUSH
**
ceph使用的数据分布式算法 **
9. RBD
RADOS Block device
ceph对外提供的块设备服务
10. RGW
RADOS gateway
ceph对外提供对象存储服务
11. cephFS
ceph file system
ceph对外提供的文件系统服务
四、ceph IO流程
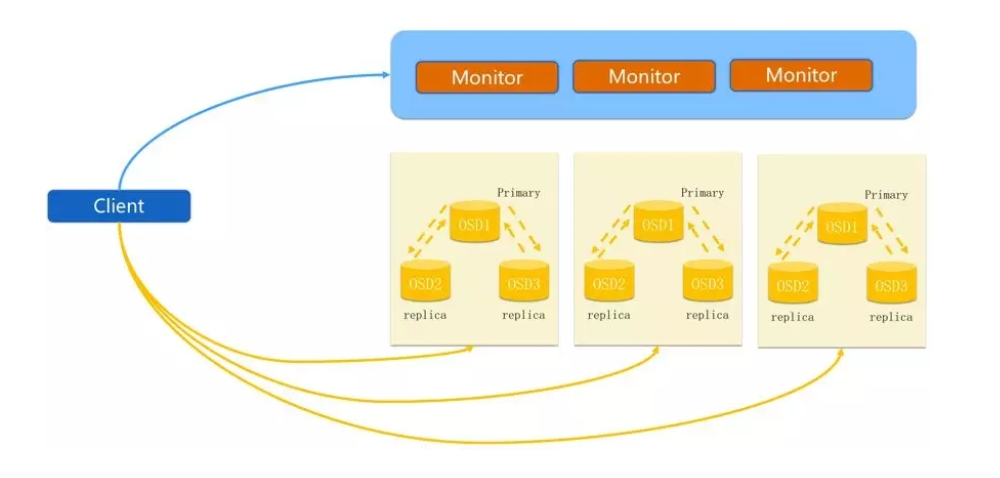
1.正常IO流程
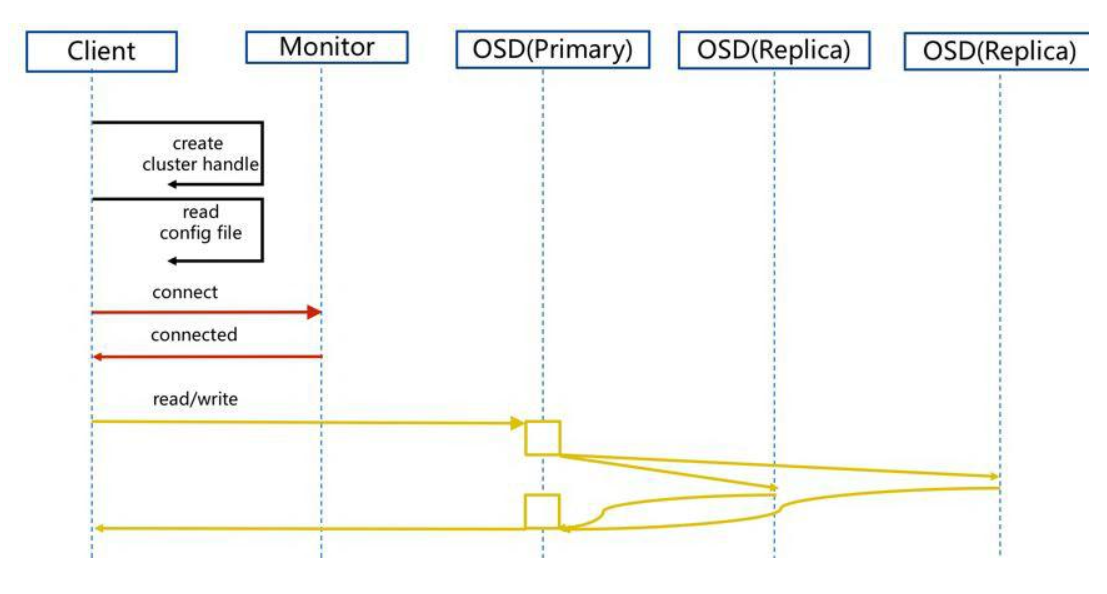
client创建cluster handler。client读取配置文件。client连接上monitor,获取集群map信息。client读写io根据crshmap算法请求对应的主osd数据节点。- 主
osd数据节点同时写入另外两个副本节点数据。 - 等待主节点以及另外两个副本节点写完数据状态。
- 主节点及副本节点写入状态都成功后,返回给
client,io写入完成。
2.新主IO流程
如果新加入的
OSD1取代了原有的OSD4成为Primary OSD, 由于OSD1上未创建PG, 不存在数据,那么PG上的I/O无法进行,怎样工作的呢?

client连接monitor获取集群map信息。- 同时新主
osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。 - 临时主
osd2会把数据全量同步给新主osd1。 client IO读写直接连接临时主osd2进行读写。osd2收到读写io,同时写入另外两副本节点。- 等待
osd2以及另外两副本写入成功。 osd2三份数据都写入成功返回给client, 此时client io读写完毕。- 如果
osd1数据同步完毕,临时主osd2会交出主角色。 osd1成为主节点,osd2变成副本。
3.ceph IO算法流程
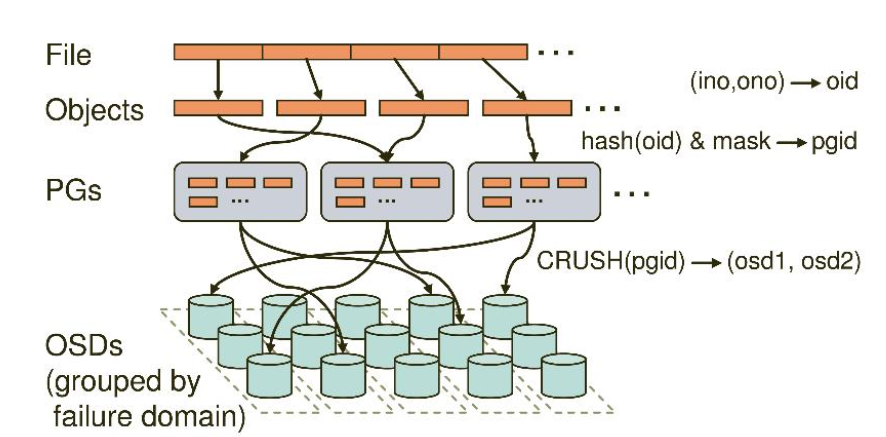
File用户需要读写的文件File->Object映射:
inoFile的元数据,File的唯一idonoFile切分产生的某个object的序号,默认以4M切分一个块大小oidobject id: ino + ono
Object是RADOS需要的对象。Ceph指定一个静态hash函数计算oid的值,将oid映射成一个近似均匀分布的伪随机值,然后和mask按位相与,得到pgid Object->PG映射:
- hash(oid) & mask-> pgid
- mask = PG总数m(m为2的整数幂)-1
PG(Placement Group),用途是对object的存储进行组织和位置映射, (类似于redis cluster里面的slot的概念) 一个PG里面会有很多object。采用CRUSH算法,将pgid代入其中,然后得到一组OSD。PG->OSD映射:
- CRUSH(pgid)->(osd1,osd2,osd3) 。
五、ceph心跳机制
1.OSD节点监听端口
OSD节点会监听public、cluster、front和back四个端口public端口,监听来自Monitor和Client的连接cluster端口,监听来自OSD peer的连接front端口,供客户端连接集群使用的网卡,临时给集群内部间进行心跳back端口,供集群内部使用的端口,用于集群内部间进行心跳hbclient端口,发送ping心跳的message
2.OSD之间的心跳
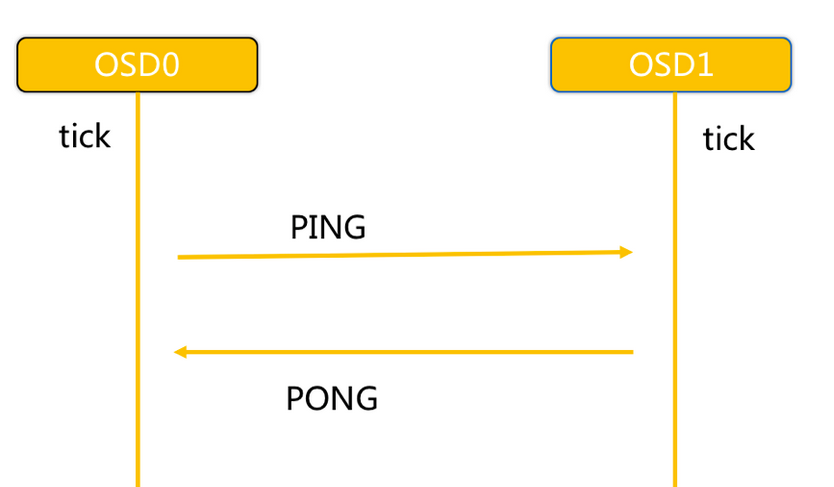
- 同一个
PG内OSD互相心跳,他们互相发送PING/PONG信息。 - 每隔
6s检测一次(实际会在这个基础上加一个随机时间来避免峰值)。 20s没有检测到心跳回复,加入failure队列。
3.OSD与Monitor间的心跳

OSD有事件发生时(比如故障、PG变更)。- 自身启动
5秒内。 OSD周期性的上报给MonitorOSD检查failure_queue中的伙伴OSD失败信息。- 向
Monitor发送失效报告,并将失败信息加入failure_pending队列,然后将其从failure_queue移除。 - 收到来自
failure_queue或者failure_pending中的OSD的心跳时,将其从两个队列中移除,并告知Monitor取消之前的失效报告。 - 当发生与
Monitor网络重连时,会将failure_pending中的错误报告加回到failure_queue中,并再次发送给Monitor。
Monitor统计下线OSDMonitor集来自OSD的伙伴失效报告。- 当错误报告指向的
OSD失效超过一定阈值,且有足够多的OSD报告其失效时,将该OSD下线。
【Linux存储系列教程】ceph的架构和原理
https://www.wsjj.top/archives/104
评论